推荐系统中的排序技术
Contents
在工业应用中,推荐系统通常可分为两部分,召回和排序。
召回阶段对应的是之前几篇文章所讲的各种推荐算法,比如据资料所载,Spotify至少使用了三种算法来生成其广受赞誉的Discover Weekly歌单,包括:
- 矩阵分解来学习集体智慧;
- NLP处理音乐评论文章与报道;
- 对音频使用卷积神经网络进行分析。
这些算法各有特点,音频分析显然可以用于解决冷启动问题,NLP处理音乐评论更是可以学得专业人士的领域知识,它们各自独立运行给出自己的结果,由于独立,算法数目可增可减,亦可各自独立迭代变化。
这个过程会从几千万item中筛选出几百或者上千的候选集,然后在排序阶段选出30首歌曲给到每位用户。这个排序可理解为一个函数,$F(user, item, context)$,输入为用户、物品、环境,输出一个0到1之间的分数,取分数最高的几首。这一过程通常称为CTR预估。
这篇文章来说一下该“函数”的常见形式及基本运作方式。
LR
最简单的是逻辑回归(Logistic Regression),一个广义线性模型。
拿某user的用户画像(一个向量)比如[3, 1],拼接上某item的物品画像比如[4, 0],再加上代表context的向量[0, 1, 1]后得到[3, 1, 4, 0, 0, 1, 1],若该user曾与该item发生过联系则label为1,这些加起来是一个正样本,同时可以将用户“跳过”的item或热门的却没有与用户产生过联系的item作为负样本,label为0,拟合如下方程:
$$
y = \frac{1}{1 + e ^ {- (w ^ {T}x + w_0)}}
$$
其中$x$即为上述向量,$w$是与x每个元素相对应的权重,$b$为截距。其损失函数为:
$$
loss =\sum_{(x, y) \in D}-y \log \left(y^{\prime}\right)-(1-y) \log \left(1-y^{\prime}\right)
$$
其中$y$为样本的label0或1,$y^{\prime}$是根据模型预测的0到1之间的数字。
通过降低此损失函数来拟合训练样本来完成模型的训练,利用模型对新的数据进行预测即完成了打分。训练过程参考sklearn的LogisticRegression很容易完成。
传统的LR只能在线下批量处理大量数据,无法有效处理大规模的在线数据流。模型更新可能要一天甚至更多,不够及时。而Google在2013提出了Follow The Regularized Leader(FTRL),一种在线逻辑回归算法。该方法对逻辑回归的目标函数进行了修改,加上各种系统工程上的调优,使得该模型的参数可以在每一个线上数据点进行动态更新。
可以在网上找到不少FTRL的开源实现比如libftrl-python。
FM | FFM
FM与FFM分别是Factorization Machine与Field-aware Factorization Machine的简称。
LR作为广义线性模型对特征向量与label之间的非线性关系会很苦手。这时便需要进行特征组合,比如使用线性模型来预测各种近似长方形形状的面积,两个特征为长$x_1$与宽$x_2$,那么显然并不能学到一个很好的模型,此时增加一个新的特征$x_3=x_1 * x_2$,便可以得到很好的效果。
在实际应用中,特征向量的维度是很高的,很难像上例中直接看到这种有意义的组合,考虑所有特征两两组合则线性回归方程变为:
$$
y(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n} w_{i j} x_{i} x_{j}
$$
除了原本特征的$i$个权重外还要学习各特征组合情况对应的权重,对于参数$w_{ij}$的训练,需要大量$x_i$和$x_j$都不为0的样本,然而由于one-hot编码等原因带来的稀疏性使得这个要求无法达成,那么训练样本不足便会导致$w_{ij}$的不准确,从而影响模型的质量。
解决方案是使用矩阵分解。在推荐系统中会对user_item_matrix做分解,为user及item学得一个低维的向量来代表自已。那么此处的情况可以与之类比,将特征组合的所有权重表示为一个形状为(i * i)的矩阵,那么$w_{ij}$即为此矩阵第i行第j列的数值,将此高维度的矩阵进行分解,可以为每个特征得到一个关于权重的隐向量$v_i$,那么$w_{i j}$使用$v_i$点乘$v_j$即可得到。此时线性方程变为:
$$
y(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}
$$
以上模型称为因子分解机(Factorization Machine),经过一些数学上的变换及处理,该模型可以在$O(kn)$的复杂度下进行训练和预测,是一种比较高效的模型。
在FM的基础上有人提出了Field-aware Factorization Machine。比如特征向量中有200多维来代表一个user的国家,country.uk和country.us等等,那么这200多个特征可以认为是属于一个field,区别在为特征$x_i$学习隐向量时要为每一个field都学到一个相应的隐向量,特征组合权重$w_{ij}$根据$x_i$关于$x_j$所在field的隐向量乘以$x_j$关于$x_i$所属field的隐向量而得,线性方程变为:
$$
y(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i, f_{j}}, \mathbf{v}_{j, f_{i}}\right\rangle x_{i} x_{j}
$$
该方法效果更好,而预测时间复杂度升至$O(kn^2)$。有开源库libffm的实现以供使用。
GBDT & LR
Facebook在广告CTR预估上的做法是使用梯度提升决策树(GBDT) & LR的方案。
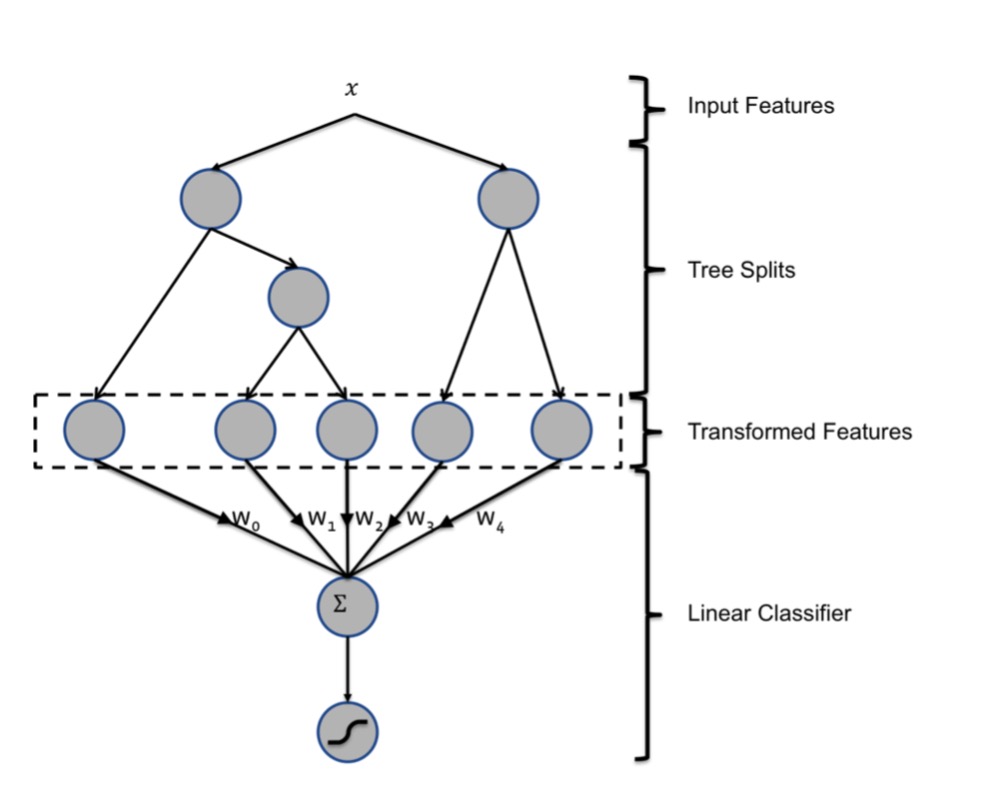
思路是将原本要输入LR的特征向量,先经过GBDT筛选和组合,生成新的特征向量再送到LR中。如图所示:
GBDT作为集成模型,会使用多棵决策树,每棵树去拟合前一棵树的残差来得到很好的拟合效果。一个样本输入到一棵树中,会根据各节点的条件往下走到某个叶子节点,将此节点值置为1,其余置为0。比如训练使用了3棵决策树,每棵决策树有5个叶子节点,样本在各树分别落到了各树从左往右的第1,2,3个节点上,则得到三个one-hot编码为[1, 0, 0, 0, 0],[0, 1, 0, 0, 0],[0, 0, 1, 0, 0],拼接起来作为转换后的特征向量:[1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0],输入到LR模型中得到分值。
此模型为Facebook的广告效果带来了明显的提升,在其发表的论文中,还讨论了各种工程上的实践与细节,包括GBDT与LR的更新频率,降采样的比例实践等,值得参考。实现GBDT可以使用开源的XGBoost包。
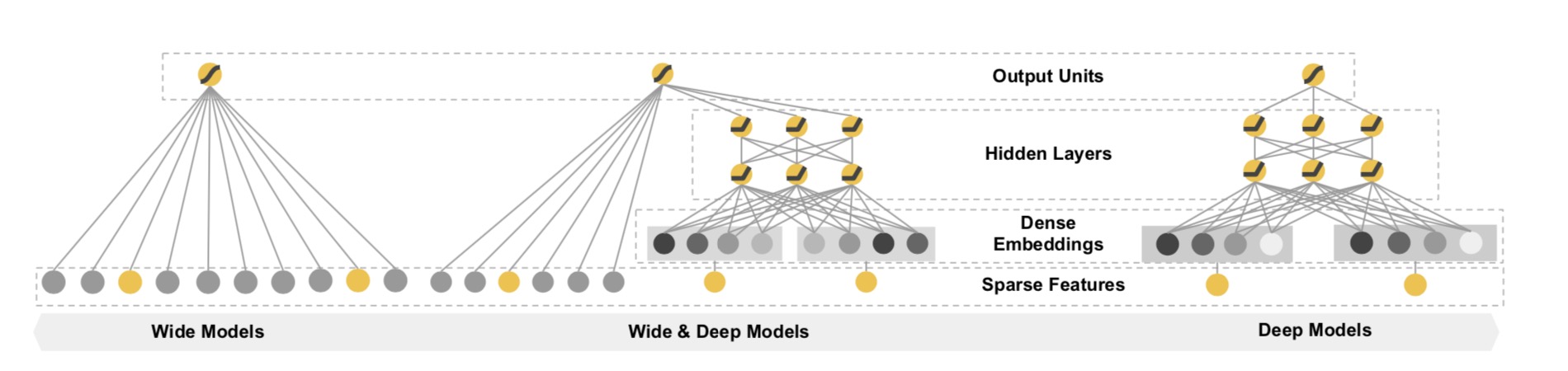
Wide & Deep
Google在Google Play中对App的推荐排序使用了一种名为Wide & Deep的深宽模型。如下图:
Wide部分就是广义的线性模型,在原本的特征基础上适当加一些特征组合,Deep部分是一个前馈神经网络,可以对一些稀疏的特征学习到一个低维的稠密向量,将Wide与Deep的信息相加,依然使用Sigmond来预测函数,表示为:
$$
P(Y=1 | \mathbf{x})=\sigma\left(\mathbf{w}_{w i d e}^{T}[\mathbf{x}, \phi(\mathbf{x})]+\mathbf{w}_{d e e p}^{T} a^{\left(l_{f}\right)}+b\right)
$$
其中$\sigma$为Sigmond函数,$W_{wide}^T$是Wide部分的权重,$\phi(\mathbf{x})$表示Wide部分的组合特征,$a^{\left(l_{f}\right)}$为Deep网络最后一层输出,$b$是线性模型的偏重。
将两个模型放到一起联合训练(不同于集成训练需要将各模型单独训练再将结果汇合),互相弥补对方的不足(特征工程困难和可解释性差),该模型为Google Play的在线收益相较于纯Wide模型带来了3.9%的提升。实现可参考tensorflow/models项目。