此篇使用朴素的代码介绍基于邻域的协同过滤算法机制。
为了使说明过程更清楚,这里使用自已编造的数据。每一行记录着某用户对某本书的评分,评分区间为1至5。
1
2
3
4
5
6
7
| import pandas as pd
data_url = 'https://gist.githubusercontent.com/guerbai/3f4964350678c84d359e3536a08f6d3a/raw/f62f26d9ac24d434b1a0be3b5aec57c8a08e7741/user_book_ratings.txt'
df = pd.read_csv(data_url,
sep = ',',
header = None,
names = ['user_id', 'book_id', 'rating'])
|
1
2
3
4
5
6
| print (df.head())
print ('-----')
user_count = df['user_id'].unique().shape[0]
book_count = df['book_id'].unique().shape[0]
print ('user_count: ', user_count)
print ('book_count: ', book_count)
|
user_id book_id rating
0 user_001 book_001 4
1 user_001 book_002 3
2 user_001 book_005 5
3 user_002 book_001 5
4 user_002 book_003 4
-----
user_count: 6
book_count: 6
生成用户物品关系矩阵
现在根据加载进来的数据生成推荐系统中至关重要的用户物品关系矩阵。可以理解为数据库中的一张表,一本书为一列,一行对应一个用户,当用户看过某本书并进行评分后,在对应的位置填入分数,其他位置均置为0,表示尚未看过。
需要注意的是,矩阵取值要用下标表示,比如matrix[2][2]对应的是第三个用户对第三本书的评分情况,所以这里要做一个user_id, book_id到该矩阵坐标的对应关系,使用pandas的Series表示。
1
2
| user_id_index_series = pd.Series(range(user_count), index=['user_001', 'user_002', 'user_003', 'user_004', 'user_005', 'user_006'])
book_id_index_series = pd.Series(range(book_count), index=['book_001', 'book_002', 'book_003', 'book_004', 'book_005', 'book_006'])
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import numpy as np
def construct_user_item_matrix(df):
user_item_matrix = np.zeros((user_count, book_count), dtype=np.int8)
for row in df.itertuples():
user_id = row[1]
book_id = row[2]
rating = row[3]
user_item_matrix[user_id_index_series[user_id], book_id_index_series[book_id]] = rating
return user_item_matrix
user_book_matrix = construct_user_item_matrix(df)
print ('用户关系矩阵长这样:')
print ('-----')
print (user_book_matrix)
|
用户关系矩阵长这样:
-----
[[4 3 0 0 5 0]
[5 0 4 0 4 0]
[4 0 5 3 4 0]
[0 3 0 0 0 5]
[0 4 0 0 0 4]
[0 0 2 4 0 5]]
计算相似度矩阵
所谓相似度,我们这里使用余弦相似度,其他的还有皮尔逊相关度、欧式距离、杰卡德相似度等,个中差别暂不细表。
计算公式为:
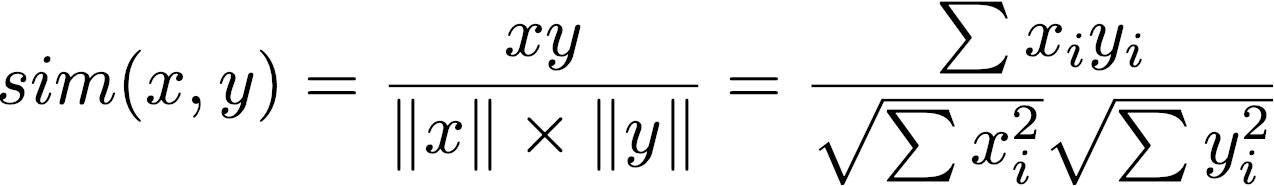
现在已经拿到了user_book_matrix,每个用户、每个物品都可以对应一个向量,比如user_book_matrix[2]为代表user_003的向量等于[4, 0, 5, 3, 4, 0],而user_book_matrix[:,2]则代表了book_003:[0, 4, 5, 0, 0, 2]。
这样基于用户和基于物品便分别可以计算出用户相似度矩阵与物品相似度矩阵。
以用户相似度矩阵为例,计算后会得到一个形状为(user_count, user_count)的矩阵,比如user_similarity_matrix[2][3]的值为0.5,则表示user_002与user_003的余弦相似度为0.5。
此矩阵为对称矩阵,相应地,user_similarity_matrix[3][2]亦为0.5,而用户与自己自然是最相似的,遂有user_similarity_matrix[n][n]总是等于1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| def cosine_similarity(vec1, vec2):
return round(vec1.dot(vec2)/(np.linalg.norm(vec1)*np.linalg.norm(vec2)), 2)
def construct_similarity_matrix(user_item_matrix, dim='user'):
if dim == 'user':
similarity_matrix = np.zeros((user_count, user_count))
count = user_count
else:
similarity_matrix = np.zeros((book_count, book_count))
count = book_count
get_vector = lambda i: user_item_matrix[i] if dim == 'user' else user_item_matrix[:,i]
for i in range(user_count):
i_vector = get_vector(i)
similarity_matrix[i][i] = cosine_similarity(i_vector, i_vector)
for j in range(i, count):
j_vector = get_vector(j)
similarity = cosine_similarity(i_vector, j_vector)
similarity_matrix[i][j] = similarity
similarity_matrix[j][i] = similarity
return similarity_matrix
user_similarity_matrix = construct_similarity_matrix(user_book_matrix)
book_similarity_matrix = construct_similarity_matrix(user_book_matrix, dim='book')
print ('user_similarity_matrix:')
print (user_similarity_matrix)
print ('book_similarity_matrix:')
print (book_similarity_matrix)
|
user_similarity_matrix:
[[1. 0.75 0.63 0.22 0.3 0. ]
[0.75 1. 0.91 0. 0. 0.16]
[0.63 0.91 1. 0. 0. 0.4 ]
[0.22 0. 0. 1. 0.97 0.64]
[0.3 0. 0. 0.97 1. 0.53]
[0. 0.16 0.4 0.64 0.53 1. ]]
book_similarity_matrix:
[[1. 0.27 0.79 0.32 0.98 0. ]
[0.27 1. 0. 0. 0.34 0.65]
[0.79 0. 1. 0.69 0.71 0.18]
[0.32 0. 0.69 1. 0.32 0.49]
[0.98 0.34 0.71 0.32 1. 0. ]
[0. 0.65 0.18 0.49 0. 1. ]]
推荐
有了相似度矩阵,可以开始进行推荐。
首先可以为用户推荐与其品味相同的用户列表,这在知乎、豆瓣、网易云音乐这样具有社交属性的产品中很有意义。
做法很简单,要为用户A推荐K位品味相似的用户(此处K取3),则将user_similarity_matrix中关于A的那一行的值排序从最高往下取出K位即可。
1
2
3
4
5
6
| def recommend_similar_users(user_id, n=3):
user_index = user_id_index_series[user_id]
similar_users_index = pd.Series(user_similarity_matrix[user_index]).drop(index=user_index).sort_values(ascending=False).index[:n]
return np.array(similar_users_index)
print ('recommend user_indexes %s to user_001' % recommend_similar_users('user_001'))
|
recommend user_indexes [1 2 4] to user_001
同时在物品维度,类似的推荐也是很有用的,比如QQ音乐给用户正在听的音乐推荐相似的歌曲,还有亚马逊中对用户刚购买的物品推荐相似的物品。
代码与推荐相似用户相同,无需做其他处理。
1
2
3
4
5
6
| def recommend_similar_items(item_id, n=3):
item_index = book_id_index_series[item_id]
similar_item_index = pd.Series(book_similarity_matrix[item_index]).drop(index=item_index).sort_values(ascending=False).index[:n]
return np.array(similar_item_index)
print ('recommend item_indexes %s to book_001' % recommend_similar_items('book_001'))
|
recommend item_indexes [4 2 3] to book_001
接下来是为用户推荐书籍,首先选出与该用户最相似的K个用户,然后找出这K个用户评过分的书籍的集合,再去掉该用户已经评过分的部分。
在剩下的书籍中,根据下面的公式,计算出该用户为某书籍的预计评分,将评分从高到低排序输出即可。
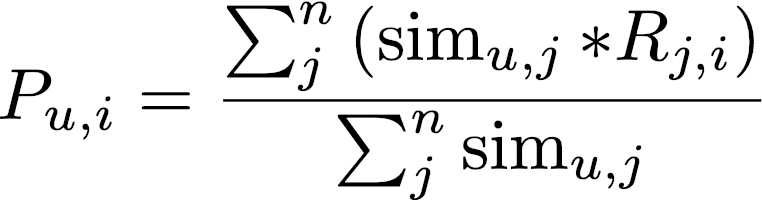
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| def recommend_item_to_user(user_id):
user_index = user_id_index_series[user_id]
similar_users = recommend_similar_users(user_id, 2)
recommend_set = set()
for similar_user in similar_users:
recommend_set = recommend_set.union(np.nonzero(user_book_matrix[similar_user])[0])
recommend_set = recommend_set.difference(np.nonzero(user_book_matrix[user_index])[0])
predict = pd.Series([0.0]*len(recommend_set), index=list(recommend_set))
for book_index in recommend_set:
fenzi = 0
fenmu = 0
for j in similar_users:
if user_book_matrix[j][book_index] == 0:
continue
fenzi += user_book_matrix[j][book_index] * user_similarity_matrix[j][user_index]
fenmu += user_similarity_matrix[j][user_index]
if fenmu == 0:
continue
predict[book_index] = round(fenzi/fenmu, 2)
return predict.sort_values(ascending=False)
recommend_item_to_user('user_005')
|
3 4.0
2 2.0
dtype: float64
以上是利用用户相似度矩阵来为用户推荐物品,同样也可以反过来为利用物品相似度矩阵来为用户推荐书籍。
做法是,找出该用户读过的所有书,为每本书找出两本与该书最相似的书籍,将找出来的所有书去掉用户已读过的,然后为书籍预测被用户评分的分值。
这里的确有些绕,容易与上文缠在一起搞乱掉,遂举例如下:
比如user_001读过书book_001, book_002,book_005,找到的书籍集合再去掉用户已读过的结果为{'book_003', 'book_006'},要为book_003预测分数,需要注意到它同时被book_001与book_005找出,要根据它们、用户对book_001与book_005的评分以及相似度套用至上文公式,来得出对book_003的分数为:(4*0.79+5*0.71)/(0.79+0.71)=4.47。
则基于物品为用户推荐物品的函数为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def recommend_item_to_user_ib(user_id):
user_index = user_id_index_series[user_id]
user_read_books = np.nonzero(user_book_matrix[user_index])[0]
book_set = set()
book_relation = dict()
for book in user_read_books:
relative_books = recommend_similar_items(book, 2)
book_set = book_set.union(relative_books)
book_relation[book] = relative_books
book_set = book_set.difference(user_read_books)
predict = pd.Series([0.0]*len(book_set), index=list(book_set))
for book in book_set:
fenzi = 0
fenmu = 0
for similar_book, relative_books in book_relation.items():
if book in relative_books:
fenzi += book_similarity_matrix[book][similar_book] * user_book_matrix[user_index][similar_book]
fenmu += book_similarity_matrix[book][similar_book]
predict[book] = round(fenzi/fenmu, 2)
return predict.sort_values(ascending=False)
recommend_item_to_user_ib('user_001')
|
2 4.47
5 3.00
dtype: float64
总结
以上是基于领域的协同过滤的运作机制介绍,只用了两个简单的数学公式,加上各种代码处理,便可以为用户做出一些推荐。
就给用户推荐物品而言,基于用户与基于物品各有特点。
基于用户给出的推荐结果,更依赖于当前用户相近的用户群体的社会化行为,考虑到计算代价,它适合于用户数较少的情况,同时,对于新加入的物品的冷启动问题比较友好,然而相对于物品的相似性,根据用户之间的相似性做出的推荐的解释性是比较弱的,实时性方面,用户新的行为不一定会导致结果的变化。
基于物品给出的推荐结果,更侧重于用户自身的个体行为,适用于物品数较少的情况,对长尾物品的发掘好于基于用户,同时,新加入的用户可以很快得到推荐,并且物品之间的关联性更易懂,是更易于解释的,而且用户新的行为一定能导致结果的变化。
显然,基于物品总体上要优于基于用户,历史上,也的确是基于用户先被发明出来,之后Amazon发明了基于物品的算法,现在基于用户的产品已经比较少了。
参考
Intro to Recommender Systems: Collaborative Filtering
【近邻推荐】人以群分,你是什么人就看到什么世界
架构师特刊:推荐系统(理论篇)
美团推荐算法实践