Song2vec
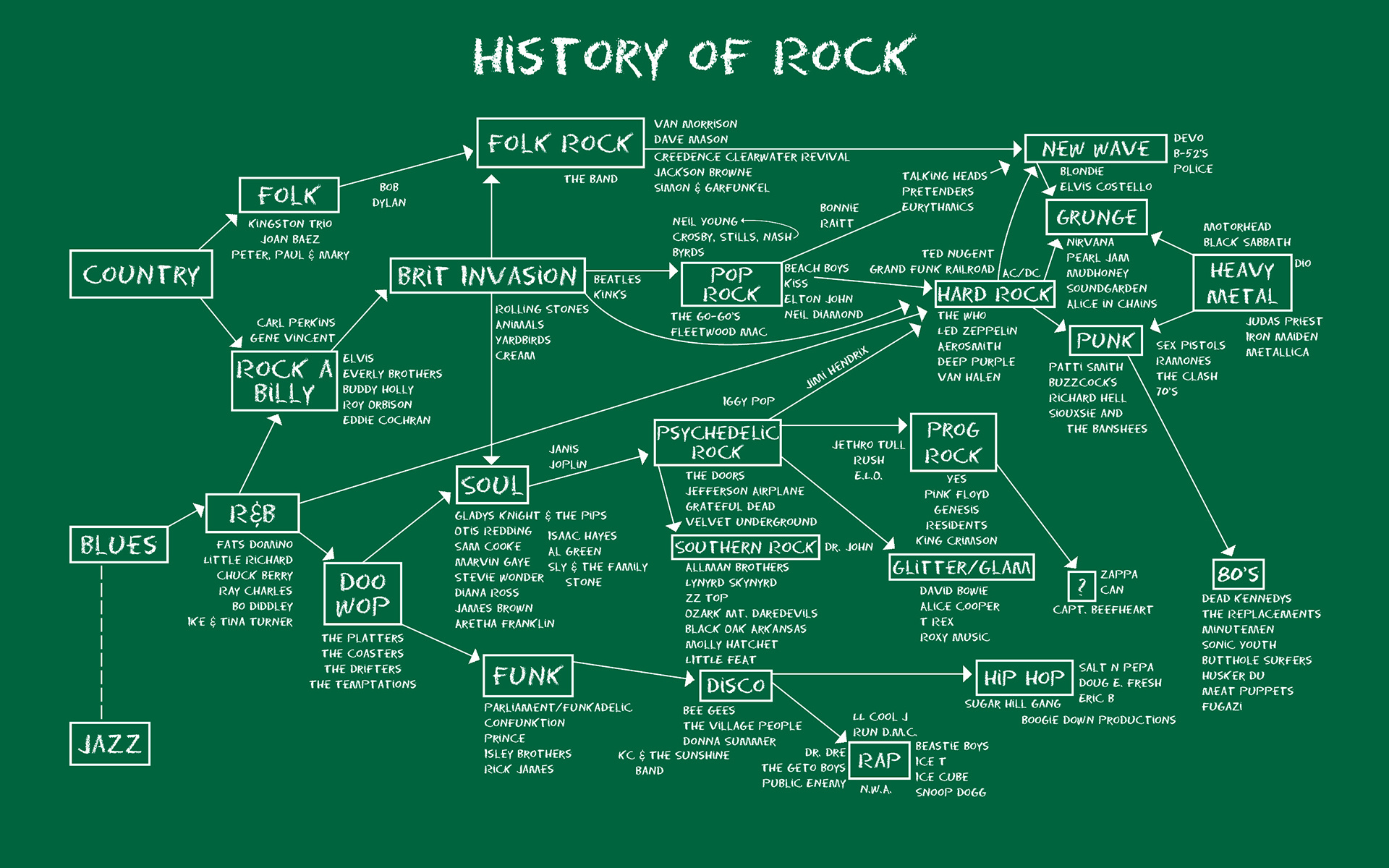
摇滚乐经过几十年的发展,风格流派众多,从blues,到brit invasion,之后是punk,disco,indie rock等等。发展历程大致是这样的:
摇滚乐的听众,总是能体会到发现宝藏的快乐,可能突然就会邂逅某支自己不曾接触过的歌曲、乐队、风格,感觉好听得不行,以前怎么从来不知道,接下来的一段时间便会沉浸于此,每天都在听该风格的主要乐队和专辑。用户收听音乐在一段时间内可能是有着某个“主题”的,这个主题可能是地理上的(俄罗斯的摇滚乐队),可能是时间上的(2000年后优秀的专辑),还可能是某流派、甚至是都被某影视作品用作BGM。之前很少听国内摇滚的笔者,在去年听了刺猬、P.K.14、重塑雕像的权利、新裤子、海朋森等一些国内乐队的很多作品后,才知道原来在老崔、窦唯、万青、老谢之外还有这么多优秀的国产摇滚乐。
这种“在某一时间会被用户放到一起听”的co-occurrence歌曲列表在音乐软件里的形态是playlist或radio,由editor或用户编辑生成,当然,还有”专辑“这个很强的联系,特别是像《The Dark Side of the Moon》这样的专辑。然而在前几篇文章提到的内容中,最为核心的数据结构是用户物品关系矩阵,这里面并没有包含”一段时间“这个信息。这段时间可以称为session,在其他领域的实际应用中,这个session可能是一篇研究石墨烯的论文,可能是一个Airbnb用户某天在30分钟内寻找夏威夷租房信息的点击情况。把session内的co-occurrence关系考虑进去,可以为用户做出更符合其当下所处情境的推荐结果。
这篇文章使用Word2vec处理Last.fm 1K数据集,来完成这种纳入session信息的歌曲co-occurrence关系的建立。
Word2vec与音乐推荐
Word2vec最初被提出是为了在自然语言处理(NLP)中用一个低维稠密向量来表示一个word(该向量称为embedding),并进一步根据embedding来研究词语之间的关系。它使用一个仅包含一层隐藏层的神经网络来训练被分成许多句子的数据,来学习词汇之间的co-occurrence关系,其中训练时分为CBOW(Continuous Bag-of-Words)与Skip-gram两种方式,这里简单说一下使用Skip-gram获取embedding的过程。
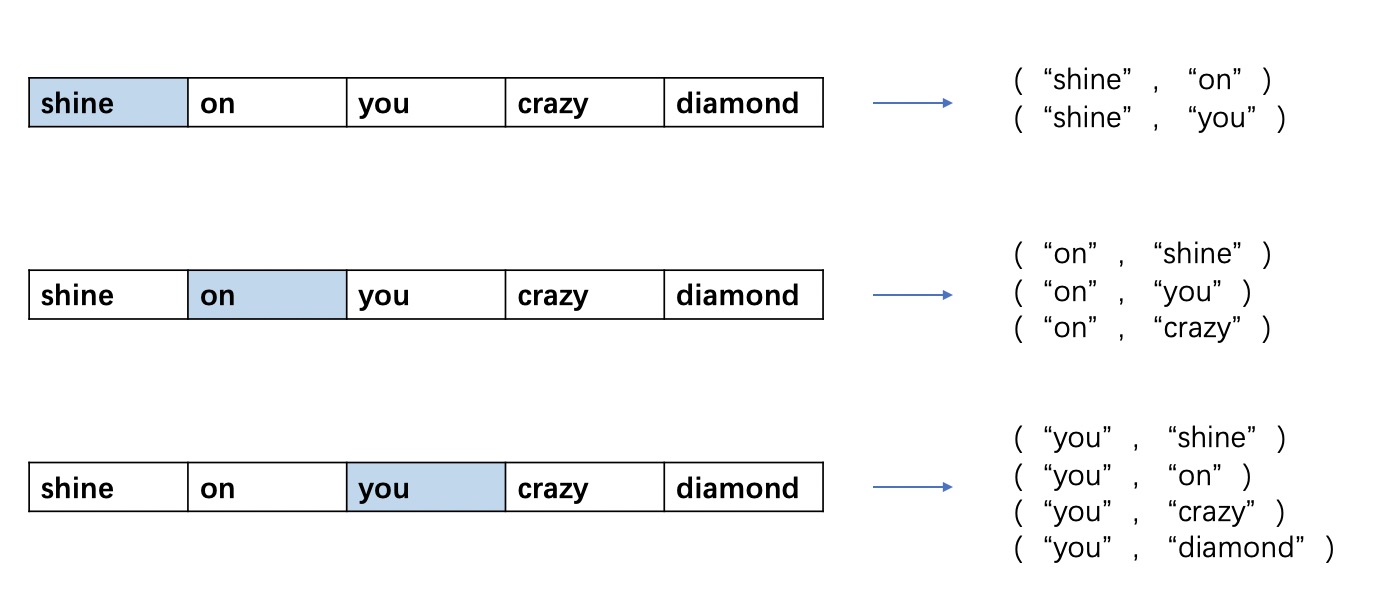
假设拿到了一些句子作为数据集,要为该神经网络生成训练样本,这里要定义一个窗口大小比如为2,则对”shine on you crazy diamond”这句话来讲,将窗口从左滑到右,按照下图方式生成一系列单词对儿,其中每个单词对儿即作为一个训练样本,单词对儿中的第一个单词为输入,第二个单词为label。
假设语料库中有10000个互不相同的word,首先将某个单词使用one-hot vector(10000维)来表示输入神经网络,输出同样为10000维的vector,每一维上的数字代表此位置为1所代表的one-hot vector所对应的word在输入word周围的可能性:
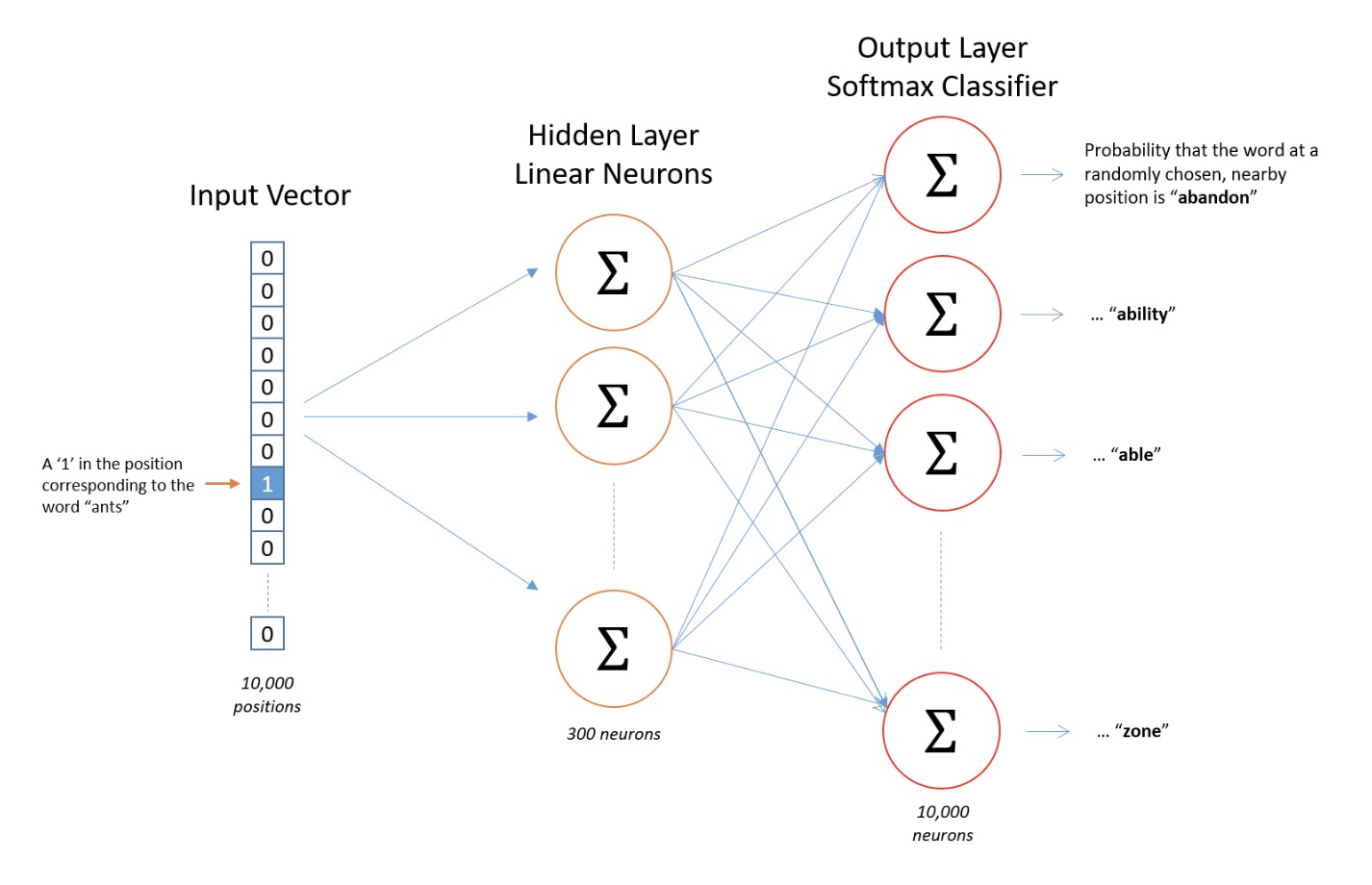
输入输出层的节点数为语料库word数,隐藏层的节点数则为表示每个单词的向量的维数。此模型每个输入层节点会与隐藏层的每个节点相连且都对应了一个权重,而对某输入节点来说,它与隐藏层相连的所有这些权重组成的向量即为该节点为1所代表的one-hot vector所对应的单词的embedding向量。
但该模型其实并不了解语义,它拥有的只是统计学知识,那么既然可以根据one-hot vector来标识一个word,当然可以用这种形式来标识一首歌曲,一支乐队,一件商品,一间出租屋等等任何可以被推荐的东西,再把这些数据喂给模型,同样的训练过程,便可以获取到各种物品embedding,然后研究它们之间的关系,此谓Item2vec,万物皆可embedding。
故Word2vec与音乐推荐的关系就是,把一个歌单或者某个user在一个下午连续收听的歌曲当作一句话(session),把每首歌当作一个独立的word,然后把这样的数据交给此模型去训练即可获取每首歌的embedding向量,这里从歌单到一句话的抽象,即实现了上文中提到的考虑进去“一段时间”这个点。
加载数据
该数据集包含了1K用户对960K歌曲的收听情况,文件1915万行,2.4G,每行记录了某用户在某时间播放了某歌曲的信息。依然是用pandas把数据加载进来,这次需要timestamp的信息。
1 | import arrow |
<class 'pandas.core.frame.DataFrame'>
Int64Index: 16936136 entries, 10 to 19098861
Data columns (total 5 columns):
user_id object
timestamp object
artist_name object
track_id object
track_name object
dtypes: object(5)
memory usage: 775.3+ MB
接下来做一些辅助的数据,为每个user、每首track都生成一个用于标识自己的index,建立从index到id,从id到index的双向查询dict。
1 | df['user_id'] = df['user_id'].astype('category') |
考虑到专辑翻唱、同名、专辑重新发行等情况,需要用track_id来作为一首歌的唯一标识,而当需要通过artist_name,track_name来定位到一首歌时,这里写了一个函数,采取的策略是找到被播放最多的那一个。
1 | def get_hot_track_id_by_artist_name_and_track_name(artist_name, track_name): |
1 | print ('wish you were here tracks:') |
wish you were here tracks:
track_id
60969 feecff58-8ee2-4a7f-ac23-dc8ce7925286
4401932 f479e316-56b4-4221-acd9-eed1a0711861
17332322 2210ba38-79af-4881-97ae-4ce8f32322c3
--------
hotest one:
feecff58-8ee2-4a7f-ac23-dc8ce7925286
生成sentences文件
加载过数据后接下来要生成在科普环节提到的由歌名歌单生成句子,由于懒,没有去爬云音乐的歌单数据,这里粗暴地将每个用户每一天收听的所有歌曲作为一个session,使用上文生成的track_index来标识各歌曲,将生成的sentences写到磁盘上。
1 | def generate_sentence_file(df): |
1 | generate_sentence_file(df) |
100%|██████████| 992/992 [1:22:23<00:00, 5.62s/it]
这个过程比较慢,在mac跑下来要快一个半小时。这里可以使用Spark来生成sentences.txt,若是在生产环境,可以利用大量机器资源,在单机上亦可以享受其将任务拆分成map、reduce来并行处理的便利,以如下Spark代码来生成Sentences.txt在mac上只需要10分钟:
1 | import pyspark |
生成后的文件长这个样子:
训练模型生成embedding
有很多种方式可以获取、实现Word2vec的代码,可以用Tensorflow、Keras基于神经网络写一个,亦可以使用Google放到Google Code上的Word2vec实现,也可以在Github上找到gensim这个优秀的库使用其已经封装好的实现。
下列代码使用smart_open来逐行读取之前生成的sentences.txt文件,对内存很是友好。这里使用50维的向量来代表一首歌曲,将收听总次数不到20次的冷门歌曲筛选出去,设窗口大小为5。
1 | from smart_open import smart_open |
假如训练的数据集为歌单,一个歌单为一个句子,由于出现在同一个歌单内代表了其中歌曲的某种共性,那么会希望将所有item两两之间的关系都考虑进去,故window size的取值可以取(所有歌单长度最大值-1)/2,会取得更好的效果。这里由于是以用户和天做分割,暂且拍脑袋拍出一个10。
sample用于控制对热门词汇的采样比例,降低太过热门的词汇对整个模型的影响,比如Radiohead的creep,这里面还有个计算公式不再细说。
sg取0、1分别表示使用CBOW与Skip-gram算法,而hs取0、1分别表示使用hierarchical softmax与negative sampling。
关于negative sampling值得多说两句,在神经网络的训练过程中需要根据梯度下降去调整节点之间的weight,可由于要调的weight数量巨大,在这个例子里为2*50*960000,效率会很低下,处理方法使用负采样,仅选取此训练样本的label为正例,其他随机选取5到20个(经验数值)单词为反例,仅调整与这几个word对应的weight,会使效率获取明显提升,并且效果也很良好。随机选取的反例的规则亦与单词出现频率有关,出现频次越多的单词,越有可能会被选中为反例。
利用embedding
现在已经用大量数据为各track生成了与自己对应的低维向量,比如Wish You Were Here这首歌,这个embedding可以作为该歌曲的标识用于其他机器学习任务比如learn to rank:
1 | model.wv[str(track_id_to_track_index_dict[ |
array([-0.39100856, 0.28636533, 0.11853614, -0.41582254, 0.09754885,
0.59501815, -0.07997745, -0.28060785, -0.0384276 , -0.84899545,
0.03777567, -0.00727402, 0.6960302 , 0.44756493, -0.13245133,
-0.38473454, -0.07809031, 0.34377965, -0.19210865, -0.33457756,
-0.36364776, -0.06028108, 0.17379969, 0.46617758, -0.04116876,
0.07322323, 0.11769405, 0.42464802, 0.25167897, -0.35790011,
0.01991512, -0.10950506, 0.26131895, -0.76148427, 0.48405901,
0.61935854, -0.59583783, 0.28353232, -0.14503367, 0.3232002 ,
1.00872386, -0.10348291, -0.0485305 , 0.21677236, -1.33224928,
0.57913464, -0.06729769, -0.32185984, -0.02978219, -0.43034038], dtype=float32)
这些embedding vector之间的相似度可以表示两首歌出现在同一session内的可能性大小:
1 | shine_on_part_1 = str(track_id_to_track_index_dict[ |
similarity between shine on part 1, 2: 0.927217
similarity between shine on part 1, good times: 0.425195
稍微看下源码便会发现上述similarity函数,gensim也是使用余弦相似度来计算的,同样可以根据该相似度,来生成一些推荐列表,当然不可能去遍历,gensim内部也是使用上篇文章提到的Annoy来构建索引来快速寻找近邻的。为了使用方便写了如下两个包装函数。
1 | def recommend_with_playlist(playlist, topn=25): |
接下来假装自己在听后朋,提供几首歌曲,看看模型会给我们推荐什么:
1 | # post punk. |
track_name artist_name
0 Miss The Girl The Creatures
1 Splintered In Her Head The Cure
2 Return Of The Roughnecks The Chameleons
3 P.S. Goodbye The Chameleons
4 Chelsea Girl Simple Minds
5 23 Minutes Over Brussels Suicide
6 Not Even Sometimes The Prids
7 Windows A Flock Of Seagulls
8 Ride The Friendly Skies Lightning Bolt
9 Inmost Light Double Leopards
10 Thin Radiance Sunroof!
11 You As The Colorant The Prids
12 Love Will Tear Us Apart Boy Division
13 Slip Away Ultravox
14 Street Dude Black Dice
15 Touch Defiles Death In June
16 All My Colours (Zimbo) Echo & The Bunnymen
17 Summernight The Cold
18 Pornography (Live) The Cure
19 Me, I Disconnect From You Gary Numan
好多乐队都没见过,wiki一下发现果然大都是后朋与新浪潮乐队的歌曲,搞笑的是Love Will Tear Us Apart竟然成了Boy Division的了,这数据集有毒。。
过了半年又沉浸在前卫摇滚的长篇里:
1 | # long progressive |
track_name artist_name
0 Nutrocker Emerson, Lake & Palmer
1 Brain Salad Surgery Emerson, Lake & Palmer
2 Black Moon Emerson, Lake & Palmer
3 Parallels Yes
4 Working All Day Gentle Giant
5 Musicatto Kansas
6 Farewell To Kings Rush
7 My Sunday Feeling Jethro Tull
8 Thick As A Brick, Part 1 Jethro Tull
9 South Side Of The Sky Yes
10 Living In The Past Jethro Tull
11 The Fish (Schindleria Praematurus) Yes
12 Starship Trooper Yes
13 Tank Emerson, Lake & Palmer
14 I Think I'M Going Bald Rush
15 Here Again Rush
16 Lucky Man Emerson, Lake & Palmer
17 Cinderella Man Rush
18 Stick It Out Rush
19 The Speed Of Love Rush
20 New State Of Mind Yes
21 Karn Evil 9: 2Nd Impression Emerson, Lake & Palmer
22 A Venture Yes
23 Cygnus X-1 Rush
24 Sweet Dream Jethro Tull
人是会变的,今天她喜欢听后朋,明天可能喜欢别的,但既然我们有数学与集体智慧,问题并不大。
参考
Using Word2vec for Music Recommendations
Word2Vec Tutorial - The Skip-Gram Model
Author: Guerbai
Link: http://guerbai.github.io/2019/03/01/song2vec/
License: 知识共享署名-非商业性使用 4.0 国际许可协议