在微服务领域,使用Redis做缓存可并不是一件容易的事情。
像新浪、推特这样的应用,许许多多的热点数据全都存放在Redis这一层,打到DB层的请求并不多,可以说非常依赖缓存了。如果缓存挂掉,流量全部穿透到DB层,其必然不堪其重,整个系统也会随之瘫痪,后果非常严重。
由于缓存数据量很大,Redis快正是快在其基于内存的快速存取,而计算机的内存资源又是十分有限的,故分布式缓存集群面临着伸缩性的要求。
一致性Hash存在的意义
Redis集群中的各实例之间是并不知道对方的,需要在客户端实现路由法来将key路由到不同的redis节点。
该路由算法是关键,它必须让新上线的缓存服务器对整个分布式缓存集群影响最小,使得扩容后,整个缓存服务器集群中已经缓存的数据尽可能还被访问到。
若是使用一般的对key进行一次hash的算法,则会导致扩容后命中率极低。
如下表所示,当集群由3个节点扩容到4个节点时,会有75%的key无法命中。
| hash(key) |
hash(key)/3 |
hash(key)/4 |
是否命中 |
| 1 |
1 |
1 |
是 |
| 2 |
2 |
2 |
是 |
| 3 |
0 |
3 |
否 |
| 4 |
1 |
0 |
否 |
| 5 |
2 |
1 |
否 |
| 6 |
0 |
2 |
否 |
| 7 |
1 |
3 |
否 |
| 8 |
2 |
0 |
否 |
| 9 |
0 |
1 |
否 |
| 10 |
1 |
2 |
否 |
| 11 |
2 |
3 |
否 |
| 12 |
0 |
0 |
是 |
这可太糟糕了,当服务器数量为100台时,再增加一台新服务器,不能命中率将达到99%,这和整个缓存服务挂了一个效果。
而一致性Hash正是为了解决这个问题而出现的,该路由算法通过引入一个一致性Hash环,以及进一步增加虚拟节点层,来实现尽可能高的命中率。
使用该算法,当节点由n扩容为n+1时,命中率可保持在n/(n+1)左右。
关于该算法的具体原理与网上已经有一些说得很透彻的文章,本文不再赘述。
下面主要从代码实现及运行的方式来对此算法的效果进行展示。
本机部署多个Redis节点
要对一致性Hash进行验证,要做好准备工作,首先要有一个Redis集群。
这里我通过使用在本机上部署多个Redis实例指向不同端口来模拟这一形态。
建立项目目录:$ mkdir redis-conf
将redis的配置copy一份过来并复制为5份,分别命名为redis-6379.conf~redis-6383.conf。
需要对其内容进行一些修改才能正常启动,分别找到配置文件中的如下两行并对数字进行相应修改。
1
2
| port 6379
pidfile /var/run/redis_6379.pid
|
然后就可以分别启动了:redis-server ./redis-6379 &
可以使用redis-cli -p 6379来指定连接的redis-server。
不妨进行一次尝试,比如在6379设置key 1 2,而到6380 get 1只能得到nil,说明它们是各自工作的,已经满足可以测试的条件。

不同的节点展示
代码实现
思路是这样的:
部署4个节点,从6379到6382,通过一致性Hash算法,将key: 0~99999共100000个key分别set到这4个服务器上,然后再部署一个节点6383,这时再从0到99999开始get一遍,统计get到的次数来验证命中率是否为期望的80%左右(4/5)。
一致性Hash算法的实现严重借鉴了这篇文章,使用红黑树来做数据结构,来实现log(n)的查找时间复杂度,使用FNV1_32_HASH哈希算法来尽可能使key与节点分布得更加均匀,引入了虚拟节点,来做负载均衡。
建议读者详细看下这篇文章,里面的讲解非常详细易懂。
下面是我改写过后的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
| package org.guerbai.io.jedistry;
import redis.clients.jedis.Jedis;
import java.util.*;
class JedisProxy {
private static String[][] redisNodeList = {
{"localhost", "6379"},
{"localhost", "6380"},
{"localhost", "6381"},
{"localhost", "6382"},
};
private static Map<String, Jedis> serverConnectMap = new HashMap<>();
private static SortedMap<Integer, String> virtualNodes = new TreeMap<>();
private static final int VIRTUAL_NODES = 100;
static
{
for (String[] str: redisNodeList)
{
addServer(str[0], str[1]);
}
System.out.println();
}
private static int getHash(String str)
{
final int p = 16777619;
int hash = (int)2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
private static String getServer(String node)
{
int hash = getHash(node);
SortedMap<Integer, String> subMap =
virtualNodes.tailMap(hash);
if (subMap.isEmpty()) {
subMap = virtualNodes.tailMap(0);
}
Integer i = subMap.firstKey();
String virtualNode = subMap.get(i);
return virtualNode.substring(0, virtualNode.indexOf("&&"));
}
public static void addServer(String ip, String port) {
for (int i = 0; i < VIRTUAL_NODES; i++)
{
String virtualNodeName = ip + ":" + port + "&&VN" + String.valueOf(i);
int hash = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash);
virtualNodes.put(hash, virtualNodeName);
}
serverConnectMap.put(ip+":"+port, new Jedis(ip, Integer.parseInt(port)));
}
public String get(String key) {
String server = getServer(key);
Jedis serverConnector = serverConnectMap.get(server);
if (serverConnector.get(key) == null) {
System.out.println(key + "not in host: " + server);
}
return serverConnector.get(key);
}
public void set(String key, String value) {
String server = getServer(key);
Jedis serverConnector = serverConnectMap.get(server);
serverConnector.set(key, value);
System.out.println("set " + key + " into host: " + server);
}
public void flushdb() {
for (String str: serverConnectMap.keySet()) {
System.out.println("清空host: " + str);
serverConnectMap.get(str).flushDB();
}
}
public float targetPercent(List<String> keyList) {
int mingzhong = 0;
for (String key: keyList) {
String server = getServer(key);
Jedis serverConnector = serverConnectMap.get(server);
if (serverConnector.get(key) != null) {
mingzhong++;
}
}
return (float) mingzhong / keyList.size();
}
}
public class ConsistencyHashDemo {
public static void main(String[] args) {
JedisProxy jedis = new JedisProxy();
jedis.flushdb();
List<String> keyList = new ArrayList<>();
for (int i=0; i<100000; i++) {
keyList.add(Integer.toString(i));
jedis.set(Integer.toString(i), "value");
}
System.out.println("target percent before add a server node: " + jedis.targetPercent(keyList));
JedisProxy.addServer("localhost", "6383");
System.out.println("target percent after add a server node: " + jedis.targetPercent(keyList));
}
}
|
以上代码对参考文章进行了一些改进。
首先,参考文章的getServer方法会有些问题,当key大于最大的虚拟节点hash值时tailMap方法会返回空,找不到节点会报错,其实这时应该去找hash值最小的一个虚拟节点。我加了处理,把这个环连上了。
下面getHash方法为FNV1_32_HASH算法,可以不用太在意。
VIRTUAL_NODES的值比较重要,当节点数目较少时,虚拟节点数目越大,命中率越高。
在程序设计上也有很大的不同,我写了JedisProxy类,来做为client访问Redis的中间层,在该类的static块中利用服务器节点生成虚拟节点构造好红黑树,getServer里根据tailMap方法取出实际节点的地址,再由实际节点的地址直接拿到jedis对象,提供简单的get与set方法,先根据key拿特定的jedis对象,再进行get, set操作。
addServer静态方法给了其动态扩容的能力,可以看到在main方法中,通过调用JedisProxy.addServer("localhost", "6383")便直接增加了节点,不需要停应用。
targetPercent方法是用来统计命中率用。
当虚拟节点为5时,命中率约为60%左右,把它加大到100后,可以到达预期的80%的命中率。
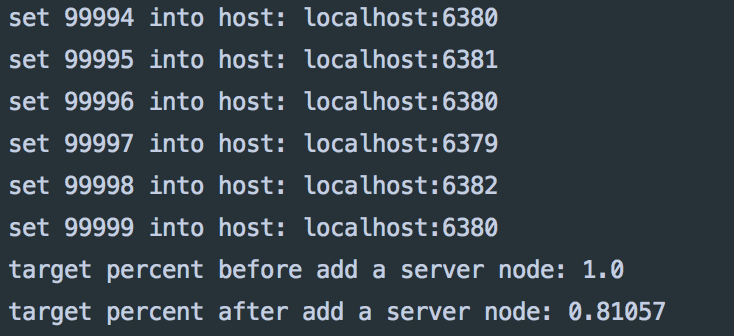
测试结果
好的,完美。